写在前面
转眼十月份了,这篇博客是通过完成一个分类问题的数据分析实验,从而总结了数据分析的基本过程,没有涉及很复杂的算法知识。
近况是参加了数学建模的国赛,准备考研
之后的博客会同步更新到我的知乎账号(https://www.zhihu.com/people/xiang-feng-60-30/activities)上
Iris数据集
首先,通过对Iris数据集的一系列处理,引入数据分析的简单步骤与常用方法,再进行分类实验。
项目背景
鸢尾属(拉丁学名:Iris L.),单子叶植物纲,鸢尾科多年生草本植物,开的花大而美丽, 观赏价值很高。鸢尾属约300种, Iris数据集中包含了其中的三种: 山鸢尾(Setosa), 杂色鸢尾(Versicolour),维吉尼亚鸢尾(Virginica),每种50个数据,共含150个数据。在每个数据包含四个属性:花萼长度,花萼宽度,花瓣长度,花瓣宽度,可通过这四个属性预测鸢尾花卉属于 (山鸢尾, 杂色鸢尾, 维吉尼亚鸢尾) 哪一类
数据集与代码:https://github.com/xiangfengw/data_analyze/tree/master/iris
数据概览
1.读取数据:
1 | import pandas as pd |
2.查看前五行数据:
1 | df_Iris.head() |
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
其中,Id为鸢尾花编号,SepaLengthCm 为花萼长度,SepalWidthCm 为花萼宽度。PetalLengthCm 为花瓣长度, 单位,PetalWidthCm; 为花瓣宽度,Species为鸢尾花种类.
3.查看数据整体信息与统计信息
1 | df_Iris.info() |
1 | Out: |
1 | df_Iris.describe() |
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | |
|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 75.500000 | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 43.445368 | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 1.000000 | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 38.250000 | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 75.500000 | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 112.750000 | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 150.000000 | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
通过以上信息我们可以得到数据集有150行,6列,其中4列为64位浮点数,1列为64位整数,1列为python对象,无缺失值,并且对四种特征值的范围也有了一定了解。
1 | df_Iris.describe(include=["O"]).T |
| count | unique | top | freq | |
|---|---|---|---|---|
| Species | 150 | 3 | Iris-versicolor | 50 |
include默认只计算数值型特征的统计量,当输入参数include=[‘O’],会计算离散型变量的统计特征
详见官方文档
该数据集总数150,包含3个种类,最大频数为50,这里每种都为50个,因此top里的指的不是Iris-versicolor最多,而是在频数相同的基础上按照字符串长度进行排名的结果。
可以通过这样对每种进行计数:
1 | df_Iris.Species.value_counts() |
1 | Out: |
特征工程(进行数据清洗与可视化)
数据清理
目标:去掉Species特征中的’Iris-‘前缀字符
方法:
1.使用字符串replace()方法替换
1 | df_Iris['Species']= df_Iris.Species.str.replace('Iris-','') |
2.使用apply()方法将该列数据一个一个传递到函数中进行分割
1 | df_Iris['Species']= df_Iris.Species.apply(lambda x: x.split('-')[1]) |
apply()方法的详解可以参考官方文档
再看一下处理后的Species特征类别
1 | # unique()方法显示list类型的set形式,即不包含重复值 |
1 | Out:array(['setosa', 'versicolor', 'virginica'], dtype=object) |
数据可视化
这里使用基于matplotlib,与pandas紧密结合的seaborn库金水数据的可视化处理
1 | import seaborn as sns |

数据可视化的方法与形式多种多样,这里先不进行详细介绍了。
决策树分类
采用决策树算法对处理后的数据构建分类模型
1 | from sklearn.model_selection import train_test_split |
以上,通过对Iris数据集的处理,了解了数据分析的简单过程,也为下一步的学习打下了基础。
宽带营销响应预测
背景
目前运营商对宽带客户的预测大多采用较粗放且基于统计的预测方法,但随着电信业全业务的完成,宽带客户对电信运营商的战略意义不断提升,应用新的方法研究宽带客户预测问题迫在眉睫。
基于以往客户行为数据,进行宽带营销响应预测,预测用户对我们的宽带营销是否接受,从而进行更加精确的营销。
数据集与代码:https://github.com/xiangfengw/data_analyze/tree/master/broadband_train
数据说明
| 变量 | 说明 |
|---|---|
| CUST_ID | 客户编码 |
| GENDER | 性别 |
| AGE | 年龄 |
| TENURE | 入网时长(月) |
| CHANNEL | 营销渠道 |
| AUTOPAY | 自动充值 |
| ARPU_3M | 近三个月总ARPU值 |
| CALL_PARTY_CNT | 通话圈人数 |
| DAY_MOU | 上午平均使用流量 |
| AFTERNOON_MOU | 下午平均使用流量 |
| NIGHT_MOU | 夜间平均使用流量 |
| AVG_CALL_LENGTH | 平均通话时长 |
| BROADBAND | 宽带营销相应 0表示不响应,1表示相应 |
前备知识
pandas read_csv() 得到的对象是 DataFrame 对象,DataFrame 既可以作为一个通用型NumPy数组,也可以看作特殊的Python字典。如果将Series类看作带灵活索引的一维数组,那么DataFrame可以看作一个既有灵活的行索引又有灵活列名的二维数组,即若干有序排列的Series对象。
在对Series对象进行取值和切片操作时,很容易因为Series采用了整数索引而造成显式索引和隐式索引的混乱,因此Pandas提供了一些索引器(indexer)属性来作为取值的方法。它们不是Series对象的函数方法,而是暴露切片接口的属性。
第一种索引器是loc属性,表示取值和切片都是显式的(显式索引做切片时,结果包含最后一个索引)
第二种是iloc属性,表示取值和切片都是Python常规形式的隐式索引(左闭右开)
第三种取值属性是ix,它是两种索引器的混合形式,主要用于DataFrame对象。当然,DataFrame对象也可以使用前两种索引器。
查看DataFrame类的行、列名信息方法
1 | dfname.index.values.tolist() # 行名称 |
数据读取
1 | import pandas as pd |
查看一下数据的基本信息
1 | broadband.head() #打印出前5行,以确保数据运行正常 |
数据清洗
通过这次实验,我将数据清洗的过程总结如下:
- loc()方法选择子集
- 修改列名
- 缺失值处理
- 数据类型与格式转换
- 数据排序
- 重命名行号
- 异常值处理
选择子集
1 | broadband_data = broadband.loc[:,'CUST_ID':'AVG_CALL_LENGTH'] |
得到特征集为 broadband_data
标签集为 broadband.BROADBAND
缺失值处理
在数据表或 DataFrame 中有很多识别缺失值的方法。一般情况下可以分为两种:一种方法是通过一个覆盖全局的掩码表示缺失值,另一种方法是用一个标签值表示缺失值。
在掩码方法中,掩码可能是一个与原数组维度相同的完整布尔类型数组,也可能是用一个比特(0或1)表示有缺失值的局部状态。在标签方法中,标签值可能是具体的数据(例如用 -9999 表示缺失的整数)。另外,标签值还可能是更全局的值,比如用 NaN表示缺失的浮点数,它是 IEEE 浮点数规范中指定的特殊字符。
python缺失值有3种:None,NA,NaN
1)Python内置的None值
Pandas 可以使用的第一种缺失值标签是 None,它是一个 Python 单 体对象,经常在代码中表示缺失值。由于 None 是一个 Python 对 象,所以不能作为任何 NumPy / Pandas 数组类型的缺失值,只能用 于 ‘object’ 数组类型(即由 Python 对象构成的数组):
1 | In: vals1 = np.array([1, None, 3, 4]) |
注意:在 Python 中没有定义整数与 None 之间的运算
2)NA
3)对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据,会把缺失值和None自动替换为NaN。
1 | In: vals2 = np.array([1, np.nan, 3, 4]) |
注意:无论和 NaN 进行何种运算操作,最终结果都是 NaN
Pandas对不同类型缺失值的转换规则:
| 类型 | 缺失值转换规则 | NA标签值 |
|---|---|---|
| floating 浮点型 | 无变化 | np.nan |
| object 对象类型 | 无变化 | None或np.nan |
| integer 整数类型 | 强制转换为 float64 | np.nan |
| boolean 布尔类型 | 强制转换为 object | None或np.nan |
以上是python中缺失值的基本知识,在数据分析的过程中,对缺失值的处理要具体问题具体分析。因为属性缺失有时并不意味着数据缺失,缺失本身是包含信息的,所以需要根据不同应用场景下缺失值可能包含的信息进行合理填充。处理不完整数据集的方法主要有三大类:删除元组、数据补齐、不处理。 至于具体的方法分析与比较,可以通过这篇博客进行学习:数据分析中的缺失值处理
我们这次的数据集中,因为含有缺失值的行数不多,所以选择删除处理
1 | broadband = broadband.dropna() |
数据类型与格式转换
将GENDER(性别)和AUTOPAY(自动充值)两列特征值进行类型转换:
GENDER:1、0代表男生、女生;AUTOPAY:1代表自动充值、0代表没有自动充值
1 | gender = broadband.GENDER.copy() |
数据排序
使用pd.sort_values方法对数据进行排序,by表示按那几列进行排序,ascending=True 表示升序排列,ascending=False表示降序排列
我们选择按客户编码排序
1 | broadband = broadband.sort_values(by='CUST_ID', ascending=True) |
行号重命名
在进行一系列的数据处理过程后,会发现数据的行号被打乱了,接下来我们重命名行号
1 | broadband = broadband.reset_index(drop=True) |
异常值处理
我们使用describe()方法查看统计描述信息时,如果有不符合常理的数据出现,应该进行筛选删除。
模型构建
将数据集划分为训练集与测试集
使用sklearn.model_selection.train_test_split可以在数据集上随机划分出一定比例的训练集和测试集
1 | from sklearn.model_selection import train_test_split |
这里,我们引入交叉验证的概念
学习预测函数的参数,并在相同数据集上进行测试是一种错误的做法,这样的模型将会获得极高的分数,但对于尚未出现过的数据它则无法预测出任何有用的信息。 这种情况称为 overfitting(过拟合),为了避免这种情况,在进行(监督)机器学习实验时,通常取出部分可利用数据作为 test set(测试数据集)。
交叉验证的方法有许多,我们这里使用train_test_split()方法直接对数据集进行了划分,其他的交叉验证迭代器可以参考以下两遍博客:
分类结果的对比标准
先介绍几个概念:
精确率(Precision):被检测出来的信息当中正确的或者相关的(也就是你想要的)信息中所占的比例;
召回率(Recall):所有正确的信息或者相关的信息(wanted)被检测出来的比例。
tp–将正类预测为正类(true positive)
fn–将正类预测为负类(false negative)
fp–将负类预测为正类(false positive)
tn–将负类预测为负类(true negative)
用表格表示:
| 正确的、相关的 | 不正确的、不相关的 | |
|---|---|---|
| 检测出来的 | TP | FP |
| 未检测出来的 | FN | TN |
利用以上四个值可以计算Precision,Recall,F1
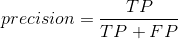
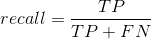
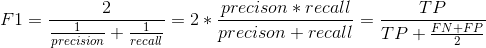
Scikit-Learn 提供了一些函数去计算分类器的指标,包括准确率和召回率。
1 | >>> from sklearn.metrics import precision_score, recall_score |
通常结合准确率和召回率会更加方便,这个指标叫做“F1 值”,特别是当你需要一个简单的方法去比较两个分类器的优劣的时候。F1 值是准确率和召回率的调和平均。普通的平均值平等地看待所有的值,而调和平均会给小的值更大的权重。所以,要想分类器得到一个高的 F1 值,需要召回率和准确率同时高。
为了计算 F1 值,简单调用f1_score()
1 | >>> from sklearn.metrics import f1_score |
网格搜索法调参
机器学习算法中有两类参数:从训练集中学习到的参数,比如逻辑斯蒂回归中的权重参数,另一类是模型的超参数,也就是需要人工设定的参数,比如正则项系数,决策树的深度,随机森林中决策树的个数,人工神经网络模型中隐藏层层数和每层的节点个数,正则项中常数大小等等,他们都需要事先指定。超参数选择不恰当,就会出现欠拟合或者过拟合的问题。而在选择超参数的时候,如果手工调整超参数,做起来十分冗长,你也可能没有时间探索多种组合。
Scikit-Learn的GridSearchCV模块可以保证在指定的参数范围内找到精度最高的参数。GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。这两个名字都非常好理解。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
需要注意的是网格搜索的评分参数scoring是可以选择的,这里我们选择为F1的值。
网格搜索虽然不错,但是穷举过于耗时,sklearn中还实现了随机搜索,使用 RandomizedSearchCV类,随机采样出不同的参数组合。
以下以决策树分类为例,对决策树的max_depth参数使用网格搜索法进行调参
1 | from sklearn.tree import DecisionTreeClassifier |
best_estimator_属性可以返回调参后的最优分类器的参数模型:
1 | DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=21, |
这里调用warnings库是为了解决pandas的SettingWithCopyWarning警告
集成算法
假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。
通过组合多个过拟合评估器来降低过拟合程度的想法其实是一种集成学习方法,集成学习方法使用并行评估器对数据进行有放回抽取集成,每个评估器都对数据过拟合,通过求均值可以获得更好的分类结果,而随机决策树的集成算法就是随机森林。
写在最后
不同算法的调用过程博客中没有详细叙述,可以直接看代码,都是直接调用的sklearn库,所以就不写了,之后准备再详细点分别整理一下各个算法的原理和实现过程。
近期的目标
读两本一直想读的书 米兰· 昆德拉的”不能承受的生命之轻” 和李诞的”笑场”
继续学习数据分析
准备开始学习计算机组成原理 复习数据结构
(假装在)坚持背英语单词
人生其实就是寻找自己的过程,学习也是一样,当你面临选择时,会犹豫会不知所措,但就像米兰· 昆德拉在”雅克和他的主人”结尾时所说:人类最古老的笑话是,你往哪走,都是往前走。